Crawlers may be directed to properly index certain pages of a website by using the robots meta tag and the X-Robots Tag. Both are contained in a URL’s HTTP header; the former is specified in the page’s HTML code.

Indexing is a multi-stage procedure that involves the following steps:
- The data is being loaded.
- Search engine robots do analysis.
- Database inclusion.
Only data that has been indexed will show up on search engine results pages. The robots meta tag and the X-Robots Tags allow you to manage the visibility and placement of specific information in search engine results.
Let’s stop fumbling about and get to the point.
Read: Understanding Crawlability and Indexability and their Impact on SEO
Where do X-Robots-Tags diverge from meta-robots tags?
It is critical to regulate how search engines will process site pages. Site owners may now have some say over their content’s visibility in search engine results pages (SERPs). Common ways of control employ the X-Robots-Tag and the meta-robots tag. Although they both achieve the same goal, their respective implementations and features set them apart.
Let’s delve deeper into them.
What Is a Meta Robots Tag?
The meta robots tag is an HTML element that instructs web crawlers, indexers, and browsers on handling a page’s content.
Insert it into the page’s <head> section for something like this to happen:
<meta name="robots" content="noindex, nofollow">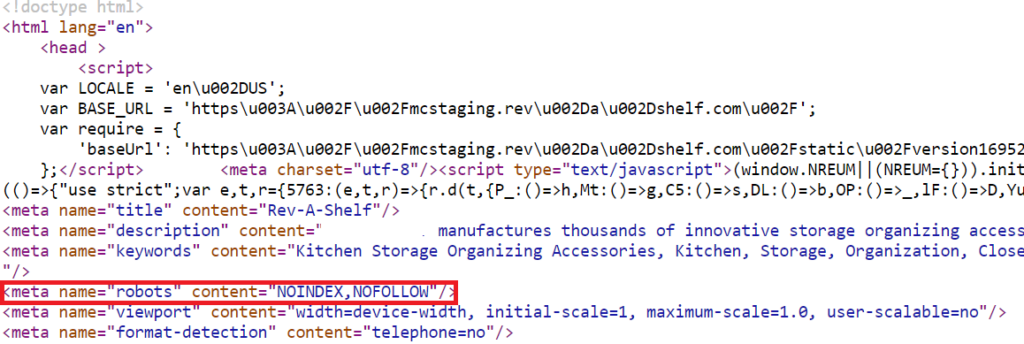
In the case above, the meta robot tag instructs all robots to avoid indexing the page.
What does a robots.txt file do?
Webmasters use the Robots.txt text file to provide rules for web robots (usually search engine robots) to follow while crawling a website. The robots.txt file is a component of the robots exclusion protocol (REP), a set of online standards that govern how web crawlers and indexing robots interact with and present material to people. Instructions for search engines on how to handle links (such as “follow” or “nofollow”) are also included in the REP as directives like meta robots and on a per-page, per-subdirectory, or per-site basis.
In reality, robots.txt files specify which user agents (web-crawling software) can crawl certain website sections. Crawl instructions may be either “disallowing” or “allowing” the actions of specific or all user agents, respectively.
Simple outline:

A robots.txt file consists of the above two lines plus any other user agent or directive lines (such as disallows, permits, crawl-delays, etc.) that may be included in the file.
Each group of user-agent instructions in a robots.txt file is separated from the others by a line break.
Each directive in robots.txt that prohibits or permits a specific user-agent applies solely to the user agents explicitly named and separated by a line break in the directive. If the file includes a rule that applies to more than one user agent, the crawler will only pay attention to (and follow the directives in) the most specific set of instructions.
Why Do We Need Robots Meta Tags?

Google’s indexing and crawling of a page’s content may be managed using robots meta tags. Whether or not to:
- Add a site to the index.
- Just click around the website!
- Images on a page may be indexed.
- Display the page’s cached version in search engine results.
- Include a preview on search engine results pages.
How Do X-Robots-Get Their Tag?
Another option for managing how spiders access and index your site is the X-Robots-Tag. It is included in the response headers of an HTTP request and regulates the indexing of the full page as well as its individual components.
On the other hand, the X-Robots-Tag is a little harder to use than meta robots tags.
But this begs the obvious query:
The X-Robots-Tag: When to Use It?
The search engine giant says, “any directive that can be used in a robots meta tag can also be specified as an X-Robots-Tag.”
Both the meta robots tag and the X-Robots-Tag may be used to specify directives relating to robots.txt in the headers of an HTTP response. However, the X-Robots-Tag is preferred in the following cases:
You need command over how non-HTML files are scanned and indexed on your site. It is preferred that site-wide instructions be wider than individual pages.
For instance, if you wish to prevent a particular picture or video from being indexed, you may do it with relative ease by using the HTTP response method.
You may use the X-Robots-Tag header to aggregate numerous tags into a single HTTP response, or you can provide directives using a comma-separated list of tags.
You may have decided that, beyond a specific date, you don’t want a certain website to be cached. Instructing search engine bots to follow these guidelines requires using the “noarchive” and “unavailable_after” tags.
The X-Robots-Tag’s strength lies in the fact that it is more adaptable than its meta-robots-tag counterpart.
Robots.txt vs. Meta-Robots
Although they perform similar tasks, meta robots tags and robots.txt files are used for distinct reasons.
The Value of the Meta Robots Tag and the X-Robots-Tag
Let’s look at the robots meta tag and the X-Robots-Tag and see how and when they may aid in SEO.
Enhanced page indexing flexibility
Thanks to X-Robots-Tag and Robots meta tags, you now have more control over how your pages are indexed. These directives allow you to control the indexing of non-HTML files, such as photos and PDFs, and whole HTML pages. You may use it on a per-page basis with robots meta tags or a per-site basis with X-Robots-Tags; the choice is yours.
Maintenance of Link Popularity
The no-follow directive may prevent link juice loss by blocking links from being followed by search engine spiders. This stops the information from being sent to other websites or internal databases.
Budget optimization for web crawling
Crawler optimization becomes increasingly critical as site size increases. Also, budgets will run out if search engines explore a website from top to bottom, preventing bots from accessing user- and SEO-friendly material. Because of this, necessary pages aren’t indexed, or at least aren’t indexed on time.
Modifying Fragments
The meta robots tag also allows you to manage the snippets on search engine results pages. The sample information shown for your pages may be customized in several ways, increasing your site’s discoverability and attractiveness in search results.
The following are some instances of snippet-controlling tags:
- The no-snippet meta tag tells search engines to suppress the page’s meta description.
- The maximum number of characters allowed in a snippet is set using the option max-snippet:[number].
- To specify the maximum number of seconds for a video preview, use the parameter max-video-preview:[number].
- Maximum image preview size (none, standard, big) is controlled by the max-image-preview:[setting] option.
Multiple commands may be merged into a single one, as in the following examples.
<meta name='robots' content='max-snippet: -1, max-image-preview:large, max-video-preview:-1'/>
Meta Robots Directives: When to Use Them
The most basic use of meta robots directives is to prevent certain pages from being indexed. Unfortunately, not every page can get organic traffic. Some of these can even worsen the site’s rankings in search engines.
The following sites should not appear in search engine results:
- Page duplication
- Filters and selection mechanisms
- A website with a search engine and page navigation
- Notifications related to the service (order completion, account activation, etc.).
- Intent-checking landing pages
- No longer current information (forecasts of upcoming events, trades, etc.)
- Non-performing, out-of-date websites
- Some pages should be hidden from search engine spiders.
The following are some of the many robots you may use in various directions to control:
- Click on the followed links.
- Indexing of resources that need to be written in HTML.
- Indexing a certain area of a webpage, etc.
The robots meta tag vs. the x-robots-tag: when to use which?

Although including an HTML sample is the simplest and most direct approach, it often falls short.
Data formats other than HTML
For example, you can’t insert the HTML code into a PDF or an image file. The only option is X-Robots-Tag.
If you’re using Apache, the following code snippet will set up noindex HTTP headers for all PDF files.
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex"
</Files>Scalable application of instructions
You may use x-robots-tags to make mass changes, such as noindexing an entire (sub) domain or subdirectory or pages with specific criteria. It’s a breeze.
Regular expressions may compare updated HTTP headers against existing URLs and filenames. Using the search and replace capability to make extensive bulk edits in HTML would often need additional time and resources.
Non-Google organic search traffic
Only a few search engines respect meta robots tags or x-robots-tags, but Google does.
For instance, the Czech search engine Seznam works solely with the robots meta tag. You cannot use x-robots-tags with this search engine to restrict the indexing and crawling of your pages. You must make use of the HTML code samples.
Read: Improve Website Visibility with Technical SEO: Ultimate Guide
Concluding Remarks
Both the robots meta tag and the X-Robots-Tag may modify a page’s indexing and subsequent visibility in search engine results. In contrast to the X-Robots-Tag, defined in the configuration file, the robots meta tag is added to the page’s code.
The following are some other salient features of each:
- The robots meta tag and X-Robots-Tag might affect which sites are indexed, whereas the robots.txt file helps search bots crawl pages appropriately. For optimal technical performance, all three are required.
- Both the robots meta tag and the X-Robots-Tag may be used to prevent sites from being indexed. However, the latter advises robots before they crawl pages, which helps save the crawl budget.
- The robots meta tag and x-robots directives are ineffective if robots.txt forbids crawling of the target page.
Indexing and website speed issues may result from improperly configured robots meta tags and the X-Robots-Tag. Carefully configure the settings or hire a professional webmaster.






